이 글은 리눅스의 문서 Documentation/DMA-API-HOWTO.txt와 배경 지식을 정리한 글이다. 메일을 읽다보니 DMA를 좀더 공부하게 됐다. 예전부터 디바이스 드라이버에 관심이 있었는데 이걸 읽고나니 디바이스와 CPU가 통신하는 매커니즘 자체는 이해한 것 같다. 물론 특정 디바이스 드라이버를 작성하려면 PCI 레이어와 디바이스가 사용하는 프로토콜(?) 관련 문서, 디바이스의 하드웨어 스펙 등등도 봐야겠지?
참고로 DMA-API-HOWTO는 API를 친절하게 설명해주는 문서라 모든 내용을 설명하지는 않는다. 더 자세한건 DMA-API 문서를 봐야한다. (이 글에는 dma_alloc_pages()나 dma_alloc_attrs() 등등은 생략되어있다.)
배경 지식
address 용어 정리
virtual address:
CPU가 메모리에 접근할 때 사용하는 가상 주소로, 접근 시에 물리 주소로 변환된다. 이 주소는 실제 RAM의 크기와는 관계가 없이 프로세서의 워드 크기에 따라서 주소의 범위가 다르다.
physical address:
실제 물리적인 메모리의 주소. 예를 들어 RAM이 4GB라면 physical address는 [0, 4GB)까지이다.
bus address = io address = device virtual address:
아키텍처에 따라서 RAM을 디바이스가 물리 주소로 직접 접근할 수도 있고, 그게 아니라 bus address로 접근할 수도 있다. 커널 관점에서는 아키텍처에 관계 없이 작동하는 API를 만들어야하기 때문에 항상 device virtual address가 존재한다고 가정하고 API를 설계해야 한다. (실제로는 physical address와 device virtual address가 같더라도)
이 용어는 virtual address / physical address와 달리 표준적인 용어가 딱히 없나보다. device address, bus address, device virtual address, io address 등등 지칭하는 말이 많은데 모두 디바이스가 메모리 접근에 사용하는 주소를 뜻한다. bus address < - > physical address 사이의 매핑은 IOMMU 또는 host bridge가 담당한다.
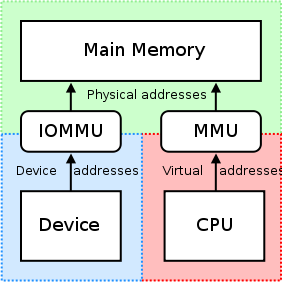
Port Mapped IO
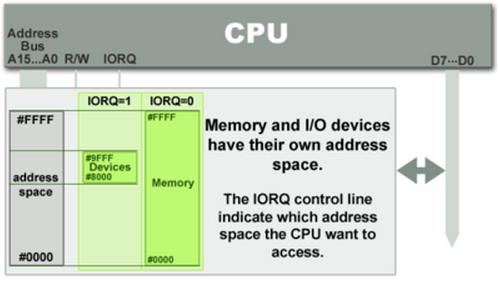
PMIO는 별도의 CPU instruction으로 디바이스의 메모리에 접근한다. 리눅스에서는 inb, outb 등의 인터페이스를 제공한다. 또한 시스템의 주소 공간과 디바이스의 주소 공간이 별개라는 특징이 있고, 따라서 접근하는 주소를 변환할 필요가 없다. inb/outb 등의 API로 접근하는 주소가 바로 디바이스의 메모리 주소와 일치하기 때문이다. 서로 다른 디바이스는 서로 다른 포트로 구분할 수 있다. 옛날에 16비트 CPU를 사용할 때는 디바이스별로 다른 주소 공간을 사용하게 하는 것이 중요했는데, 이후 레지스터 크기가 커지고 주소 공간이 늘어남에 따라서 요즘엔 크게 중요하진 않다.
Memory Mapped IO

MMIO에서는 디바이스의 메모리가 시스템의 메모리와 매핑되므로, 해당 주소에서 데이터를 읽거나 쓰기만 하면 된다. 이 방법의 단점은 어떤 물리 주소가 어떤 디바이스의 주소로 매핑되어있는지를 매번 확인해야 한다는 단점이 있다. 하지만 사실상 요즘 사용하는 거의 모든 디바이스 드라이버는 MMIO를 사용한다.
PIO (Programmed Input/Output)
PMIO와 MMIO 모두 , 디바이스와 통신하려면 메모리 읽기/쓰기 명령어든 별도의 IO 전용 읽기/쓰기 명령어든 데이터를 매번 CPU가 옮겨줘야한다. 이런 방식을 PIO라고 한다. CPU는 한 번에 데이터를 1바이트 ~ 8바이트만큼 나를 수 있고, 데이터를 한 번 읽거나 쓸 때마다 인터럽트를 처리해야 한다.
DMA (Direct Memory Access)
위에서 말했듯 PIO 방식에서는 MMIO와 PMIO 모두 디바이스와 통신하려면 CPU를 거쳐야 한다. 이렇게 하는 대신 디바이스가 직접 메모리에 접근할 수 있도록 하면 CPU가 일일이 데이터를 옮겨 주지 않고도 디바이스가 직접 메모리에 접근할 수 있다.
consistent or streaming DMA
DMA를 할 때 consistent/coherent하다는 것은, 디바이스가 메모리에 데이터를 쓸 때 별도의 동기화 매커니즘 없이 RAM과 항상 즉각적으로 동기화된다는 것을 의미한다. 따라서 별도의 작업이 없어도 CPU가 언제든지 메모리를 읽으면 그게 디바이스가 메모리에 쓴 값과 일치하게 된다. 반대로 streaming/inconsistent 하다는 것은 데이터를 버퍼에 쌓아두고 한 번만 전송을 한다는 의미이며, 따라서 디바이스나 CPU에서 데이터를 버퍼에 쓰더라도 상대방이 해당 데이터를 읽으려면 버퍼를 비우기 전까지 기다려야 한다.
scatterlist
DMA에 사용하는 주소는 물리적으로 연속되어야 한다. 왜냐하면 일반적으로 버스에서 가상 주소가 아닌 물리 주소를 사용하기 때문이다. 그렇지 않은 버스도 있지만 우리가 사용하는 대부분의 버스는 물리 주소를 사용한다. 하지만 디바이스에서 scatter/gather IO를 지원하는 경우에는 scatterlist로 물리적으로 연속적이지 않은 버퍼도 DMA에 사용할 수 있다. 참고로 나는 처음에 vmalloc()으로 할당한 버퍼는 물리적으로 연속적이지 않으니까 DMA를 할 수 없겠지 싶었는데 vmalloc()으로 할당한 버퍼도 1) 버퍼를 구성하는 각각의 페이지에 대하여 가상 주소를 물리 주소로 변환하고 2) 그걸 scatterlist로 만들면 DMA를 할 수 있다.
DMA API HOWTO
본문 시작.
https://www.kernel.org/doc/Documentation/DMA-API-HOWTO.txt
CPU and DMA addresses
커널에는 다양한 종류의 주소가 있는데 일반적으로 가상 주소를 사용한다. kmalloc(), vmalloc() 등등의 API는 가상 주소를 반환하며, 해당 주소를 void 포인터에 저장할 수 있다. 가상 메모리 시스템(TLB, 페이지 테이블 등등)은 가상 주소를 물리 주소로 변환하며 해당 주소는 phys_addr_t나 resource_size_t 타입으로 저장된다.
커널은 디바이스의 레지스터와 같은 리소스들을 물리 주소로 관리한다. 이렇게 관리되는 주소는 /proc/iomem에서 확인할 수 있다. 물리 주소는 드라이버한테 직접적으로 사용될 수는 없고 ioremap()으로 가상 주소를 만들어줘야 한다.
IO 디바이스는 물리 주소도 가상 주소도 아닌 버스 주소를 사용한다. 디바이스가 Memory-Mapped IO 주소를 사용하거나 DMA로 시스템 메모리를 읽거나 쓸 때 사용되는 주소는 버스 주소이다. 몇몇 시스템에서는 버스 주소가 물리 주소와 같지만 일반적으로는 그렇지 않다. IOMMU와 host bridge는 물리 주소와 버스 주소 간에 무작위적으로 매핑할 수 있다.
디바이스의 관점에서 DMA는 bus address space을 사용한다. 하지만 이 버스 주소 공간은 제한될 수도 있는데, 예를 들어 64비트 시스템에서 64비트인 PCI BAR(Bus Address Register)를 사용한다고 해도 IOMMU를 사용하면 32비트 DMA 주소를 사용할 수도 있다.
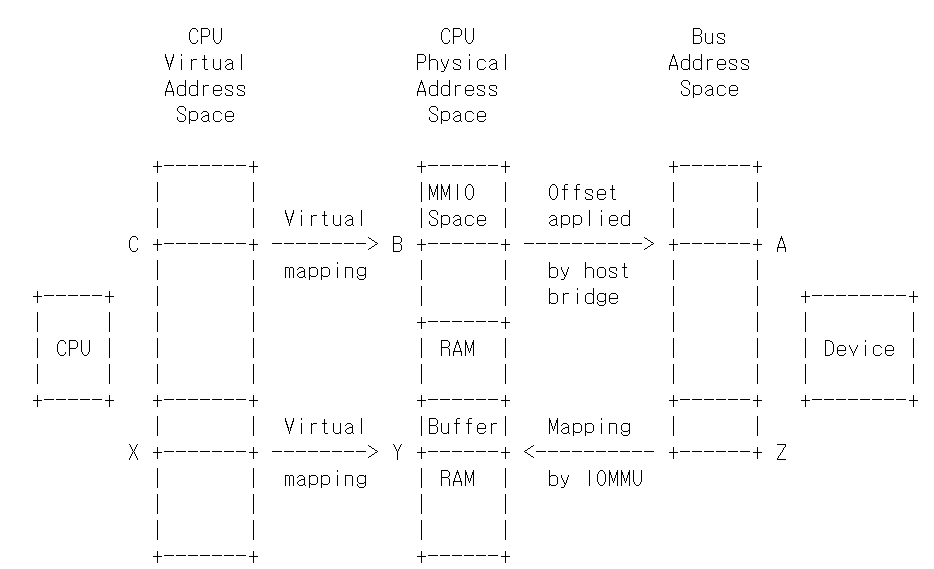
어떤 디바이스가 있는지 탐색할 때 커널은 각각의 IO 디바이스에 대한 정보와 MMIO를 위한 공간, 그리고 디바이스를 시스템과 연결하는 호스트 브리지가 무엇인지를 확인한다. 예를 들어서 PCI에 BAR이 있으면 커널은 버스 주소 (A)를 BAR에서 읽고 CPU의 물리 주소 (B)로 변환한다. 주소 B는 struct resource에 저장되며 /proc/iomem으로 노출된다. 드라이버가 디바이스를 요구할 때는 일반적으로 드라이버가 ioremap을 호출해서 물리 주소 (B)를 위한 가상 주소 (C)를 매핑한다. 그럼 이제 ioread32(C) 와 같은 방식으로 버스 주소 (A)에 존재하는 디바이스 레지스터에 접근한다.
디바이스가 DMA를 지원하면 드라이버는 kmalloc() 등등으로 버퍼를 할당하고 해당하는 버퍼에 대한 가상 주소 (X)를 얻는다. 이 때 가상 메모리 시스템이 X를 물리 주소 Y와 매핑한다. 그러면 드라이버는 가상 주소 X로 버퍼에 접근할 수 있다. 하지만 디바이스는 가상 주소 X로 버퍼에 접근할 방법이 없는데, DMA는 CPU의 가상 메모리 시스템을 고려하지 않고 물리 주소를 통해서만 작동하기 때문이다. (아무래도 DMA가 가상 메모리를 지원하려면 디바이스가 페이지 테이블을 탐색해서 가상 주소에 해당하는 물리 주소를 변환하는 기능도 탑재해야할 것이다.)
일부 단순한 시스템에서는 물리 주소 Y로 직접 DMA를 할 수 있다. 하지만 그렇지 않은 경우에는 IOMMU 하드웨어가 존재해서 DMA 주소를 물리 주소로 변환한다. (예를 들어서 DMA 주소 Z를 -> 물리 주소 Y로 변환함) 이러한 시스템이 DMA API가 존재하는 이유 중 하나다. 디바이스 드라이버가 dma_map_single()와 같은 API에 가상 주소 X를 전달하면 IOMMU 세팅을 하고 DMA 주소 Z를 반환한다. 그럼 드라이버는 주소 Z로 DMA를 수행할 수 있다. (그리고 IOMMU가 DMA 주소 Z를 물리 주소 Y에 존재하는 시스템 RAM의 버퍼와 매핑한다.)
따라서 리눅스는 동적 DMA 매핑을 사용할 수 있다. 대신 드라이버가 DMA로 데이터를 모두 전송한 후에는 API를 사용하여 다시 매핑을 해제해야 한다. 앞으로 소개할 API는 이러한 하드웨어가 없는 시스템에서도 잘 동작한다.
DMA API는 어떤 아키텍처에서 어떤 버스를 사용하든 잘 작동한다는 점을 참고하자. 버스에 특화된 API를 사용하는 것보다 DMA API를 사용하자. (예를 들어 pci_map_* 대신 dma_map*를 사용하자.)
DMA API를 사용하려면 아래 헤더파일을 사용해야 한다.
#include <linux/dma-mapping.h>
What memory is DMA'able?
DMA를 사용하려면 어떤 커널 메모리가 DMA 매핑될 수 있는지를 알아야 한다.
할당된 메모리가 페이지 할당자로 할당된 경우 (__get_free_page*()나 kmalloc(), kmem_cache_alloc()) 에는 DMA로 데이터를 읽거나 쓸 수 있다. 다시 말하면 vmalloc()으로 할당된 메모리로는 DMA를 할 수 없다 ㅡ 정확하게 말하면 vmalloc으로 할당된 가상 주소로는 DMA를 할 수 없고, 이와 매핑된 물리 주소를 알아내면 그 주소로는 DMA를 할 수 있다.
그리고 페이지 할당자로 할당된 메모리라는 말은 커널 이미지가 존재하는 주소나 (data/text/bss 세그먼트), 모듈 이미지가 존재하는 주소나, 스택 주소 등등은 사용해선 안된다는 뜻이다. 불가능한 것은 아니지만, I/O 버퍼가 캐시라인으로 정렬되어있다는 걸 고려할 때 DMA에 사용되는 주소를 제대로 정렬하지 않으면 캐시라인을 걸쳐 써서 잘못된 데이터가 덮어씌워지게 된다.
그리고 vmalloc()과 비슷한 이유로 kmap()으로 반환된 주소를 사용해서도 안된다.
DMA addressing capabilities
기본적으로 커널은 디바이스가 32비트 주소를 사용할 수 있다고 가정한다. 디바이스가 64비트 주소 접근을 지원하는 경우 64비트로 올리고, 24비트 주소 접근만 지원하는 경우 24비트로 낮추는 식이다.
드라이버는 디바이스가 몇비트 주소를 사용하는지 커널에게 아려야 한다.
int dma_set_mask_and_coherent(struct device *dev, u64 mask);이 API는 streaming mask와 coherent mask를 동시에 설정하는데, 각각을 따로 설정하려면 아래 API를 사용해야 한다.
int dma_set_mask(struct device *dev, u64 mask);int dma_set_coherent_mask(struct device *dev, u64 mask);여기서 dev는 디바이스 구조체에 대한 포인터고 mask는 디바이스에 대한 정보를 나타내는 변수이다. dev는 종종 버스에 특화된 구조체에 포함되어 있다. 예를 들어서 pci_device *pdev가 있다고 하면 &pdev->dev를 dev에 대한 포인터로 사용할 수 있다.
이 함수들은 컴퓨터에서 DMA를 수행할 수 있을 때 0을 리턴하고, 불가능한 경우에는 0이 아닌 값을 리턴한다. 위 함수들이 성공한 경우에만 DMA를 수행해야 하며, 그렇지 않을 경우에는 문제가 생길 수 있다.
따라서 위의 함수들이 실패했을 경우에는 1) DMA가 아닌 방식으로 데이터를 전송하거나 2) 디바이스를 무시해버려야 한다.
일반적인 64비트 주소 접근이 가능한 디바이스에서는 대강 이렇게 코드를 짤 수 있다.
if (dma_set_mask_and_coherent(dev, DMA_BIT_MASK(64))) {
dev_warn(dev, "mydev: No suitable DMA available\n");
goto ignore_this_device;
}아니면 coherent 에서는 32비트만 지원하지만 streaming mapping에서는 64비트를 지원하면 이렇게 할 수도 있다. 이때 dma_set_mask_and_coherent()가 아니라 dma_set_mask()를 호출한다는 걸 주의해서 보자. coherent mask는 기본적으로 32비트이므로 설정하지 않고, streaming mask만 64비트로 설정한 것이다.
if (dma_set_mask(dev, DMA_BIT_MASK(64))) {
dev_warn(dev, "mydev: No suitable DMA available\n");
goto ignore_this_device;
}디바이스가 24비트 주소를 사용한다면 이렇게 마스크를 설정할 수도 있다.
if (dma_set_mask(dev, DMA_BIT_MASK(24))) {
dev_warn(dev, "mydev: 24-bit DMA addressing not available\n");
goto ignore_this_device;
}dma_set_mask()나 dma_set_mask_and_coherent()가 성공하면 커널은 mask 값을 따로 저장해놓은 후에 나중에 매핑할 때 사용한다. 성공했을 때 리턴값은 0이다.
만약 디바이스가 여러 가지 기능 (function)을 지원하는 경우 ㅡ 예를 들어 사운드 카드가 녹음과 재생을 지원하는 경우 ㅡ 그리고 각각의 기능에 서로 다른 DMA 주소 제한이 있는 경우에는 각각의 기능에 따로 mask를 설정할 필요가 있다. 다음은 이러한 상황의 예시를 수도코드로 작성한 것이다.
#define PLAYBACK_ADDRESS_BITS DMA_BIT_MASK(32)
#define RECORD_ADDRESS_BITS DMA_BIT_MASK(24)
struct my_sound_card *card;
struct device *dev;
...
if (!dma_set_mask(dev, PLAYBACK_ADDRESS_BITS)) {
card->playback_enabled = 1;
} else {
card->playback_enabled = 0;
dev_warn(dev, "%s: Playback disabled due to DMA limitations\n",
card->name);
}
if (!dma_set_mask(dev, RECORD_ADDRESS_BITS)) {
card->record_enabled = 1;
} else {
card->record_enabled = 0;
dev_warn(dev, "%s: Record disabled due to DMA limitations\n",
card->name);
}Types of DMA mappings
DMA 매핑에는 두가지 타입이 있다.
Consistent DMA 매핑은 보통 드라이버 초기화에 사용되며, 초기화가 끝나면 보통 매핑을 해제한다. Consistent DMA 매핑을 사용하면 별도적인 동기화 / flushing 없이 CPU와 디바이스가 메모리를 병렬로 액세스할 수 있다. "consistent"라는 말이 "synchronous", "coherent"와 같다고 생각하면 편하다.
일단 현재 구현 상으로는 기본적으로 API가 consistent memory를 반환한다. 하지만 추후 바뀔 수도 있으므로 consistent mask를 명시적으로 설정해서 API를 호출하자.
consistent 매핑을 사용하는 예제는 여러 가지가 있다.
- 네트워크 카드의 DMA 링 디스크립터
- SCSI 어댑터 mailbox 명령어의 자료구조
- 메인 메모리 외부에서 실행되는 디바이스 펌웨어의 마이크로코드
이 예시들 모두 CPU가 메모리에 저장하면 디바이스에서도 즉시 반영이 되어야하고 반대도 성립해야 한다. Consistent 매핑을 사용하면 서로 메모리를 수정했을 때 즉각적으로 반영되는 것이 보장된다.
그리고 이건 중요한 부분인데, Consistent DMA 메모리를 사용한다고 메모리 배리어를 사용하지 않아도 되는 건 아니다. (배리어를 사용하라는 뜻) 만약 디스크립터의 첫 번째 워드가 두 번째 워드보다 반드시 먼저 설정되어야 한다면 메모리 배리어로 순서가 바뀌지 않도록 보장해줘야한다. 그렇지 않으면 CPU가 명령어의 실행 순서를 바꿀 수도 있다.
// barrier example
desc->word0 = address;
wmb();
desc->word1 = DESC_VALID;그리고 일부 플랫폼에서는 드라이버가 CPU의 쓰기 버퍼를 flush해야할 수도 있다. (PCI 브리지에서 쓰기 버퍼를 flush 하는 것처럼 ㅡ 예를 들어 레지스터의 값을 쓴 후에 읽는 방법으로 말이다.)
- Consistent DMA 매핑에서 데이터를 쓸 때마다 전송해서 동기화하는 것과 다르게 Streaming DMA 매핑은 데이터를 버퍼에 쌓아두었다가 단 한번만 전송한다. "streaming"을 "asynchronous"나 "outside the coherency domain"이라고 생각하면 편하다.
streaming 매핑을 사용하는 예시는 다음과 같다.
- 네트워크 디바이스가 수신/송신하는 네트워크 버퍼
- SCSI 디바이스가 읽고 쓰는 파일시스템 버퍼
streaming DMA 매핑을 위한 인터페이스는 최적화 구현을 위해서 설계되었다. streaming DMA 매핑에서는 데이터를 읽고 쓰는 것을 명시적으로 알려야 한다.
streaming/consistent DMA 매핑 모두 주소 정렬에 대한 제한은 없지만 일부 디바이스에서는 정렬 제한이 있을 수도 있다. 그리고 DMA-coherent하지 않은 캐시를 사용하는 시스템에서는 버퍼가 다른 데이터랑 캐시라인을 공유하지 않을 때 더 잘 작동한다.
Using Consistent DMA mappings
페이지 크기보다 큰 consistent DMA 영역을 매핑하려면 dma_alloc_coherent API를 사용하자. (dev는 struct device * 타입이다.)
dma_addr_t dma_handle;
cpu_addr = dma_alloc_coherent(dev, size, &dma_handle, gfp);이 API에서는 DMA 영역를 위한 RAM를 할당한다. (__get_free_pages()를 할당하는거랑 비슷하지만 page order 대신 사이즈를 받는다) 만약 드라이버가 페이지보다 작은 영역을 할당한다면 이후에 설명할 dma_pool을 사용하는 것이 좋다.
consistent DMA 매핑 인터페이스는 기본적으로 32bit addressable한 DMA 주소를 반환한다. 디바이스가 DMA 마스크로 32비트보다 상위 주소를 사용할 수 있다고 명시하더라도 dma_set_coherent_mask()로 DMA 마스크가 명시적으로 바뀌었다면 consistent allocation은 32비트보다 큰 주소만 할당할 것이다. (문장이 이상한데 실제로 문서에 이렇게 쓰여있다.) 이건 dma_pool에서도 똑같다.
dma_alloc_coherent()는 두 개의 값을 리턴하는데, 하나는 CPU로 접근할 수 있는 가상 주소이고 나머지 하나는 카드에 보낼 dma_handle이다.
CPU 가상 주소와 DMA 주소는 모두 요청한 크기보다 크거나 같은 가장 작은 PAGE_SIZE order에 맞춰서 정렬된다. 이 제한은 (예를 들어) 64 킬로바이트보다 작거나 같은 크기로 할당했을 때 버퍼의 경계가 64K를 넘지 않도록 보장하기 위함이다.
DMA 영역을 해제하려면 dma_free_coherent()를 호출하면 된다. 이 함수는 인터럽트에서 호출될 수 없다.
dma_free_coherent(dev, size, cpu_addr, dma_handle);만약 드라이버가 페이지 크기보다 더 작은 영역을 사용한다면 dma_alloc_coherent()로 할당받은 메모리를 쪼개는 코드를 작성할 수도 있다. dma_pool은 이런 상황을 위해서 존재한다. dma_pool은 kmem_cache와 비슷하지만 __get_free_pages() 대신 dma_alloc_coherent()를 사용한다. 그리고 dma_pool은 kmem_cache보다 하드웨어의 정렬에 대한 제한을 이해하고 있다. (예를 들어서 큐 헤드가 N바이트 경계로 정렬되는 것처럼)
dma_pool은 dma_pool_create로 만들 수 있다.
struct dma_pool *pool;
pool = dma_pool_create(name, dev, size, align, boundary);할당은 dma_pool_alloc()으로 할 수 있는데, 여기서 flags는 블록할 수 있는 컨텍스트인 경우 GFP_KERNEL, 그렇지 않으면 GFP_ATOMIC이다.
cpu_addr = dma_pool_alloc(pool, flags, &dma_handle);free는 dma_pool_free()로 할 수 있다.
dma_pool_free(pool, cpu_addr, dma_handle);dma_pool를 사용한 다음에는 dma_pool_destroy()로 제거해주자.
dma_pool_destroy(pool);DMA Direction
consistent DMA 매핑은 암묵적으로 양방향으로 데이터를 주고 받을 수 있지만, streaming DMA 매핑에서는 DMA의 방향을 정해야 한다. (예를 들어 NIC에서 데이터를 수신한다면 디바이스 -> CPU 방향이고, 송신한다면 CPU -> 디바이스 방향이다.) DMA의 방향은 네 가지가 있다.
DMA_BIDIRECTIONAL
DMA_TO_DEVICE
DMA_FROM_DEVICE
DMA_NONE이때 DMA_TO_DEVICE는 CPU에서 디바이스로 전송할 때, DMA_FROM_DEVICE는 디바이스에서 CPU로 전송할 때, DMA_BIDIRECTIONAL은 양방향 모두가 가능할 때를 나타낸다. DMA의 방향을 정확하게 모를 때는 DMA_BIDIRECTIONAL를 사용해도 좋지만, 가능한 경우(확실히 방향을 아는 경우)에는 최대한 DMA_FROM_DEVICE나 DMA_TO_DEVICE로 설정을 해두는게 좋다. 그래야 버스에 따라서 최적화할 수도 있고, 디버깅에 용이하다. 몇몇 플랫폼은 DMA 방향이 DMA_TO_DEVICE만 명시되어있는데 해당 주소에서 데이터를 읽으려고 할 경우, 사용자 주소 공간에서 메모리 보호를 하는 것처럼 디바이스에서도 읽지 못하게 보호할 수 있다.
SCSI 서브시스템은 SCSI 명령어의 sc_data_direction이라는 필드로 DMA의 방향을 나타낸다.
네트워크 드라이버에서는 더 간단하다. 송신 패킷에는 DMA_TO_DEVICE를 사용하고 수신 패킷에는 DMA_FROM_DEVICE를 사용하면 된다.
Using Streaming DMA mappings
streaming DMA 매핑 루틴은 인터럽트 컨텍스트에서도 호출할 수 있다. streaming DMA 매핑은 맵/언맵 각각 두 가지 버전의 API가 있는데, 하나는 단일 메모리 영역을 때 사용하고, 나머지 하나는 scatterlist를 할당할 때 사용한다.
우선 dma_map_single()로 단일 영역을 매핑하는 예시를 살펴보자.
struct device *dev = &my_dev->dev;
dma_addr_t dma_handle;
void *addr = buffer->ptr;
size_t size = buffer->len;
dma_handle = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_handle)) {
/*
* reduce current DMA mapping usage,
* delay and try again later or
* reset driver.
*/
goto map_error_handling;
}
[...]
dma_unmap_single(dev, dma_handle, size, direction);dma_map_single()이 실패했을 때는 dma_mapping_error()를 호출해야 한다. 그래야 모든 DMA 구현에서 실제 구현과 관계 없이 DMA 매핑 코드가 올바르게 동작한다. 만약 에러를 체크하지 않고 반환된 주소를 그냥 사용해버리면 데이터 오염에서 커널 패닉까지 다양한 문제가 발생할 수 있다. dma_map_page()도 마찬가지다.
DMA 전송이 끝난 후에는 dma_unmap_single()로 매핑을 해제해야 한다. 예를 들어 DMA 전송이 끝났다는 인터럽트를 처리할 때 dma_unmap_single()로 해제할 수 있다.
그런데 HIGHMEM 메모리 같은 경우에는 직접적으로 포인터로 넘겨서 DMA를 할 수가 없으므로 struct page를 넘기는 방식으로 DMA를 할 수 있다. 이때 page는 DMA를 할 페이지, offset은 해당 페이지로부터의 바이트 오프셋이다.
struct device *dev = &my_dev->dev;
dma_addr_t dma_handle;
struct page *page = buffer->page;
unsigned long offset = buffer->offset;
size_t size = buffer->len;
dma_handle = dma_map_page(dev, page, offset, size, direction);
if (dma_mapping_error(dev, dma_handle)) {
/*
* reduce current DMA mapping usage,
* delay and try again later or
* reset driver.
*/
goto map_error_handling;
}
...
dma_unmap_page(dev, dma_handle, size, direction);dma_map_single()에서 했던 것처럼 매핑에 실패하면 dma_mapping_error()를 호출해야 한다. 그리고 DMA가 끝나면 dma_unmap_page()로 매핑을 해제해야한다. (예를 들어 DMA가 끝나서 인터럽트가 발생하면)
scatterlist를 사용하는 경우에는 여러 개의 영역을 하나의 집합으로 만들 수 있다. (nents는 sglist의 원소 개수)
int i, count = dma_map_sg(dev, sglist, nents, direction);
struct scatterlist *sg;
for_each_sg(sglist, sg, count, i) {
hw_address[i] = sg_dma_address(sg);
hw_len[i] = sg_dma_len(sg);
}이때 count는 sglist의 원소 개수를 나타내는데, 인접한 원소가 합쳐진 경우에는 count < nents일 수 있다.
dma_unmap_sg(dev, sglist, nents, direction);dma_unmap_sg()로 매핑을 해제할 수 있다. 이때 dma_unmap_sg()의 nents 파라미터는 count가 아니라 dma_map_sg()를 호출할 때 사용했던 nents와 반드시 같아야 한다.
일반적으로 dma_map_{single,sg}를 호출하면 dma_unmap_{single,sg}로 매핑을 해제해주어야 한다. 왜냐하면 DMA 주소 공간이 공유자원이기 때문이다. 만약 하나의 매핑을 여러 번 사용하려면 DMA가 끝난 후 CPU와 디바이스를 동기화해주어야 한다. 그래서 DMA 수행 후 버퍼에 데이터를 읽거나 쓴다면 dma_map_{single,sg}를 호출한 후 다음 두 함수중 하나를 호출해서 CPU가 변경된 내용을 확인할 수 있도록 동기화해야한다. 다시 말해 DMA 이후에 버퍼의 내용을 CPU가 확인해야한다면 먼저 동기화를 해줘야 한다.
dma_sync_single_for_cpu(dev, dma_handle, size, direction);
dma_sync_sg_for_cpu(dev, sglist, nents, direction);그 다음 CPU에서 버퍼를 수정한 후 다시 디바이스에 DMA를 수행하려면 다음 두 함수중 하나를 호출하면 된다. 아래 함수들을 호출하면 DMA 버퍼가 디바이스와 동기화된다. 주의할 점은 dma_sync_sg_for_device()를 호출할 땐 nents의 값이 dma_map_sg()를 호출했을 때의 값과 반드시 같아야 한다.
dma_sync_single_for_device(dev, dma_handle, size, direction);
dma_sync_sg_for_device(dev, sglist, nents, direction);이번엔 DMA를 사용하는 간단한 예제를 살펴보자.
my_card_setup_receive_buffer(struct my_card *cp, char *buffer, int len)
{
dma_addr_t mapping;
mapping = dma_map_single(cp->dev, buffer, len, DMA_FROM_DEVICE);
if (dma_mapping_error(cp->dev, mapping)) {
/*
* reduce current DMA mapping usage,
* delay and try again later or
* reset driver.
*/
goto map_error_handling;
}
cp->rx_buf = buffer;
cp->rx_len = len;
cp->rx_dma = mapping;
give_rx_buf_to_card(cp);
}
...
my_card_interrupt_handler(int irq, void *devid, struct pt_regs *regs)
{
struct my_card *cp = devid;
...
if (read_card_status(cp) == RX_BUF_TRANSFERRED) {
struct my_card_header *hp;
/* Examine the header to see if we wish
* to accept the data. But synchronize
* the DMA transfer with the CPU first
* so that we see updated contents.
*/
dma_sync_single_for_cpu(&cp->dev, cp->rx_dma,
cp->rx_len,
DMA_FROM_DEVICE);
/* Now it is safe to examine the buffer. */
hp = (struct my_card_header *) cp->rx_buf;
if (header_is_ok(hp)) {
dma_unmap_single(&cp->dev, cp->rx_dma, cp->rx_len,
DMA_FROM_DEVICE);
pass_to_upper_layers(cp->rx_buf);
make_and_setup_new_rx_buf(cp);
} else {
/* CPU should not write to
* DMA_FROM_DEVICE-mapped area,
* so dma_sync_single_for_device() is
* not needed here. It would be required
* for DMA_BIDIRECTIONAL mapping if
* the memory was modified.
*/
give_rx_buf_to_card(cp);
}
}
}DMA API를 사용하는 드라이버는 virt_to_bus()나 bus_to_virt()를 사용하면 안된다. 이 두 함수는 deprecated 되었고 앞으로는 사라질 것이다.
Handling Errors
- dma_alloc_coherent()가 NULL을 리턴하거나 dma_map_sg()가 0을 리턴한 경우
- dma_map_{single,sg}가 리턴한 dma_handle이 dma_mapping_error()로 에러가 확인된 경우
dma_addr_t dma_handle;
dma_handle = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_handle)) {
/*
* reduce current DMA mapping usage,
* delay and try again later or
* reset driver.
*/
goto map_error_handling;
}- 여러 개의 페이지를 매핑하다가 중간에 오류가 난 경우 - 예제 1
dma_addr_t dma_handle1;
dma_addr_t dma_handle2;
dma_handle1 = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_handle1)) {
/*
* reduce current DMA mapping usage,
* delay and try again later or
* reset driver.
*/
goto map_error_handling1;
}
dma_handle2 = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_handle2)) {
/*
* reduce current DMA mapping usage,
* delay and try again later or
* reset driver.
*/
goto map_error_handling2;
}
...
map_error_handling2:
dma_unmap_single(dma_handle1);
map_error_handling1:- 여러 개의 페이지를 매핑하다가 중간에 오류가 난 경우 - 예제 2
/*
* if buffers are allocated in a loop, unmap all mapped buffers when
* mapping error is detected in the middle
*/
dma_addr_t dma_addr;
dma_addr_t array[DMA_BUFFERS];
int save_index = 0;
for (i = 0; i < DMA_BUFFERS; i++) {
...
dma_addr = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_addr)) {
/*
* reduce current DMA mapping usage,
* delay and try again later or
* reset driver.
*/
goto map_error_handling;
}
array[i].dma_addr = dma_addr;
save_index++;
}
...
map_error_handling:
for (i = 0; i < save_index; i++) {
...
dma_unmap_single(array[i].dma_addr);
}네트워크 드라이버가 transmit hook 함수인 ndo_start_xmit()에서 DMA 매핑에 실패할 경우 dev_kfree_skb()를 호출한 후에 NETDEV_TX_OK를 리턴해야 한다. 소켓 버퍼가 실패로 인해 드랍되었다는 의미이다.
SCSI 드라이버가 queuecommand hook에서 DMA 매핑에 실패할 경우에는 SCSI_MLQUEUE_HOST_BUSY를 리턴해야한다. 그러면 SCSI 서브시스템이 해당 커맨드를 나중에 다시 드라이버에게 보낸다.
Optimizing Unmap State Space Consumption
dma_unmap_{page,single}()은 대부분의 아키텍처에서 아무 일도 하지 않는다. 하지만 이 함수가 필요한 아키텍처에서는 매핑 주소와 길이를 저장해두었다가 언맵할 때 사용해야한다. 주소와 길이를 저장하는 변수를 아키텍처에 따라서 ifdef로 감싸서 정의하면 변수를 저장할 메모리를 아낄 수 있지만 그것 나름대로 코드가 매우 복잡해진다. 다행히 DMA API에서는 이 문제를 해결하는 기능을 제공한다.
// Use DEFINE_DMA_UNMAP_{ADDR,LEN} in state saving structures.
// Example, before::
struct ring_state {
struct sk_buff *skb;
dma_addr_t mapping;
__u32 len;
};
// after::
struct ring_state {
struct sk_buff *skb;
DEFINE_DMA_UNMAP_ADDR(mapping);
DEFINE_DMA_UNMAP_LEN(len);
};
// 2) Use dma_unmap_{addr,len}_set() to set these values.
// Example, before::
ringp->mapping = FOO;
ringp->len = BAR;
// after::
dma_unmap_addr_set(ringp, mapping, FOO);
dma_unmap_len_set(ringp, len, BAR);
// 3) Use dma_unmap_{addr,len}() to access these values.
// Example, before::
dma_unmap_single(dev, ringp->mapping, ringp->len,
DMA_FROM_DEVICE);
// after::
dma_unmap_single(dev,
dma_unmap_addr(ringp, mapping),
dma_unmap_len(ringp, len),
DMA_FROM_DEVICE);Platform Issues
- scatterlist
아키텍처에서 IOMMU를 지원한다면 (소프트웨어 IOMMU도 포함해서) CONFIG_NEED_SG_DMA_LENGTH를 활성화해야한다.
- ARCH_DMA_MINALIGN
드라이버와 서브시스템은 항상 kmalloc()으로 할당한 버퍼가 DMA-safe하다고 간주하기 때문에 kmalloc()으로 할당한 버퍼는 DMA-safe해야한다. 아키텍처가 DMA-coherent 하지 않은 경우 ㅡ 다시 말해 CPU 캐시와 메인 메모리 상의 데이터가 같다고 보장할 수 없는 경우에는 캐시라인이 버퍼 외부와 겹치지 않도록 해야한다. 자세한건 arch/arm/include/asm/cache.h를 참고하자.
그리고 ARCH_DMA_MINALIGN은 DMA와 관련된 내용이므로 아키텍처의 정렬 제한을 걱정할 필요는 없다.
참고 문서
Memory-mapped I/O - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Method of CPU communication with peripherals, treating their interface the same as memory for reads and writes Memory-mapped I/O (MMIO) and port-mapped I/O (PMIO) are two complementary
en.wikipedia.org
Memory-mapped I/O - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Method of CPU communication with peripherals, treating their interface the same as memory for reads and writes Memory-mapped I/O (MMIO) and port-mapped I/O (PMIO) are two complementary
en.wikipedia.org
Tweak3D.net - How Bus Mastering Works
Tweak3D.net - How Bus Mastering Works
www.tweak3d.net
Input–output memory management unit - Wikipedia
Input–output memory management unit - Wikipedia
In computing, an input–output memory management unit (IOMMU) is a memory management unit (MMU) that connects a direct-memory-access–capable (DMA-capable) I/O bus to the main memory. Like a traditional MMU, which translates CPU-visible virtual addresses
en.wikipedia.org
linux - PCIe - DMA: Consistent vs. Streaming Memory - Stack Overflow
PCIe - DMA: Consistent vs. Streaming Memory
Currently I'm adding DMA to my PCIe driver for Linux. As I'm reading through the documentation it makes mention of consistent, or coherent, memory by using the API: pci_set_consistent_dma_mask(......
stackoverflow.com
https://lenovopress.com/lp1467.pdf
https://docs.oracle.com/cd/E19683-01/806-5222/hwovr-22/
Bus Specifics (Writing Device Drivers)
Slots D, E, and F are not actual physical slots, but refer to the onboard direct memory access (DMA), SCSI, Ethernet, and audio controllers. For convenience, these are viewed as being plugged into slots D, E, and F. Note – Some SBus slots are slave-only
docs.oracle.com
'Kernel' 카테고리의 다른 글
| Page Cache: filemap_read (3) | 2022.02.09 |
|---|---|
| VFS: read_iter() & write_iter() (0) | 2022.01.24 |
| [Linux Kernel] 리눅스는 얼마나 작아질 수 있을까? (1) | 2021.12.05 |
| [Paper] When Poll is Better than Interrupt (0) | 2021.11.06 |
| [Linux Kernel] 부팅 초기에 Abort가 나서 로그가 안보일때 (0) | 2021.10.16 |




댓글