이 글에서는 SLUB을 5.14 기준으로 분석한다. 왜 5.14 기준이냐면 이번에 5.15에서 RT-compatible하게 바뀌었는데 SLUB을 분석하면서 같이 설명하기엔 너무 복잡하기 때문이다. 5.14에서 5.15로 넘어가면서 바뀌는 부분은 별도의 글로 정리해야겠다.
SLUB은 Christoph가 SLAB의 설계상 단점을 보완하기 위해서 만든 슬랩 할당자이다. queueing을 최소화하고 대신 CPU에 특정 페이지를 담당하게 해서 TLB miss를 줄인다는 것이 가장 큰 특징이다. 그리고 SLAB보다 디버깅 기능이 좋다. 2.6.23부터 기본으로 SLUB 할당자를 사용하도록 되어있다.
SLUB이 대부분의 상황에서 선호된다. 하지만 SLUB이 SLAB을 보완하려고 만들었다고 해서 항상 SLAB보다 뛰어난 것은 아니다. David의 말에 따르면 구글은 현재 (아직까지는) production kernel에서 SLAB을 사용하고 있다. 하지만 대부분의 배포판에서는 SLUB을 기본으로 사용하고 있다. SLAB은 SLUB보다 개발이 덜 이루어지고 있다.
SLAB/SLUB의 차이는 내가 이해한 내용으로는 다음과 같다. 심심할때 perf로 둘을 비교해봐야겠다.
- SLAB은 L1, L2 캐시를 최대한 활용하도록 짜여있다. SLUB은 캐시 활용도는 SLAB보다 적더라도 가능한 한 같은 페이지에서 할당하려고 노력하기 때문에 TLB miss가 적다.
- SLUB이 오브젝트 관리에 linked list를 사용하기 때문에 SLAB보다 cache footprint가 크다.
- SLUB은 메타데이터가 SLAB처럼 많지 않아서 디버깅을 하기가 용이하다. 실제로 디버깅 기능도 SLAB보다 뛰어나다.
- SLAB은 복잡한 queue를 유지하느라 메모리를 많이 사용하는데 SLUB은 그것보다 간단하다.
- remote node에 대한 free는 SLAB이 더 빠르다. (대신 그만큼 메모리를 많이 사용함)
아래 글에선 Christoph가 왜 SLUB을 만들었는지 잘 설명해준다.
The SLUB allocator [LWN.net]
The slab allocator has been at the core of the kernel's memory management for many years. This allocator (sitting on top of the low-level page allocator) manages caches of objects of a specific size, allowing for fast and space-efficient allocations. Kerne
lwn.net
SLUB: The unqueued slab allocator V6 [LWN.net]
SLUB: The unqueued slab allocator V6 From: Christoph Lameter To: akpm@osdl.org Subject: [SLUB 0/2] SLUB: The unqueued slab allocator V6 Date: Sat, 31 Mar 2007 12:30:56 -0700 (PDT) Cc: linux-mm@kvack.org, linux-kernel@vger.kernel.org, Christoph La
lwn.net
Data structures
구조체 정의보단 그림이 더 이해하기 간단할 것 같아서 Christoph의 PPT 중 한 페이지를 올려본다.
[Linux Kernel] SL[AUO]B: Kernel memory allocator design and philosophy
내가 SLAB/SLUB을 잘못 이해했는지 Christoph Lameter 아저씨가 발표한 영상을 한 번 보라고 추천해주셨다. 이 글은 SL[AUO]B: Kernel memory allocator design and philosophy를 정리하고 내 의견을 추가로 적은..
hyeyoo.com

사진에서 kmem_cache는 캐시를 표현하는 디스크립터이다. kmem_cache_node는 노드별로 필요한 데이터를 관리하는 구조체고 kmem_cache_cpu는 오브젝트의 할당과 해제를 할때 사용하는 per cpu 데이터이다.
다만 위의 PPT에서 현재 유효하지 않은 두 가지가 있는데 하나는 struct page가 PPT와 달라졌다는 것이고 나머지 하나는 FP (Free Pointer)는 이제 오브젝트 안에 존재할 경우 처음이 아니라 중간에 존재하게 된다. (보안상의 이유로)
struct page
아래는 SLUB의 경우에 struct page의 일부를 단순화한 것이다. 여담이지만 최근에 Matthew가 memory folio랑 관련해서 슬랩 관련 필드를 struct slab으로 분리하려고 하는듯 하다. 머지가 될지는 모르겠지만 가까운 미래에 바뀔 수도 있다.
struct page {
...
struct { /* slab, slob and slub */
union {
struct list_head slab_list;
struct { /* Partial pages */
struct page *next;
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
};
};
struct kmem_cache *slab_cache; /* 해당 페이지를 사용하는 캐시 포인터 */
void *freelist; /* 페이지 내 free object 포인터 */
union {
unsigned long counters;
struct {
unsigned inuse:16; /* 페이지 내 할당된 오브젝트 수 */
unsigned objects:15; /* 페이지 내 전체 오브젝트 수 */
unsigned frozen:1; /* 현재 페이지가 frozen 상태인지 여부 */
};
};
};
...
}Let's read comments first
*
* Lock order:
* 1. slab_mutex (Global Mutex)
* 2. node->list_lock
* 3. slab_lock(page) (Only on some arches and for debugging)
*Lock order는 말 그대로 락을 획득하는 순서이다. 순서를 지키지 않으면 데드락이 발생할 수 있다.
* slab_mutex
*
* The role of the slab_mutex is to protect the list of all the slabs
* and to synchronize major metadata changes to slab cache structures.slab_common 분석에서 알아봤듯 slab_mutex는 슬랩 전체에서 사용하는 광범위한 락이다. 옛날에 커널에 존재하던 BKL과 같은 존재이다.
* The slab_lock is only used for debugging and on arches that do not
* have the ability to do a cmpxchg_double. It only protects:
* A. page->freelist -> List of object free in a page
* B. page->inuse -> Number of objects in use
* C. page->objects -> Number of objects in page
* D. page->frozen -> frozen stateSLUB은 fastpath에서 lockless하게 할당을 하는데, cmpxchg_double을 지원하는 아키텍처에서만 lockless fastpath를 구현할 수 있으므로 불가능한 경우에는 slab_lock을 사용한다. slab_lock은 디버깅 용으로도 사용한다.
* If a slab is frozen then it is exempt from list management. It is not
* on any list except per cpu partial list. The processor that froze the
* slab is the one who can perform list operations on the page. Other
* processors may put objects onto the freelist but the processor that
* froze the slab is the only one that can retrieve the objects from the
* page's freelist.어떤 CPU가 슬랩 (슬랩 서브시스템에서 관리하는 자료구조)을 freeze하면 per-cpu partial list를 제외하고는 리스트 상에에서 존재하지 않는다. 이때 페이지를 freeze한 CPU만 freelist에서 할당할 수 있다. 그 외의 CPU는 해당 페이지에서 할당했던 오브젝트를 free만 할 수 있다. 나는 이게 처음에 이해가 잘 안됐는데, 그래서 이걸 그림으로 한번 나타내봤다.
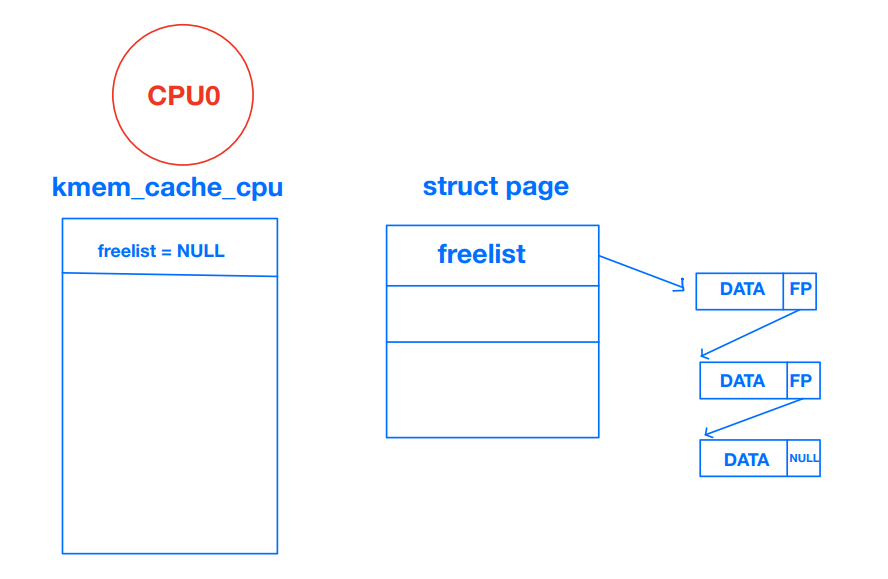
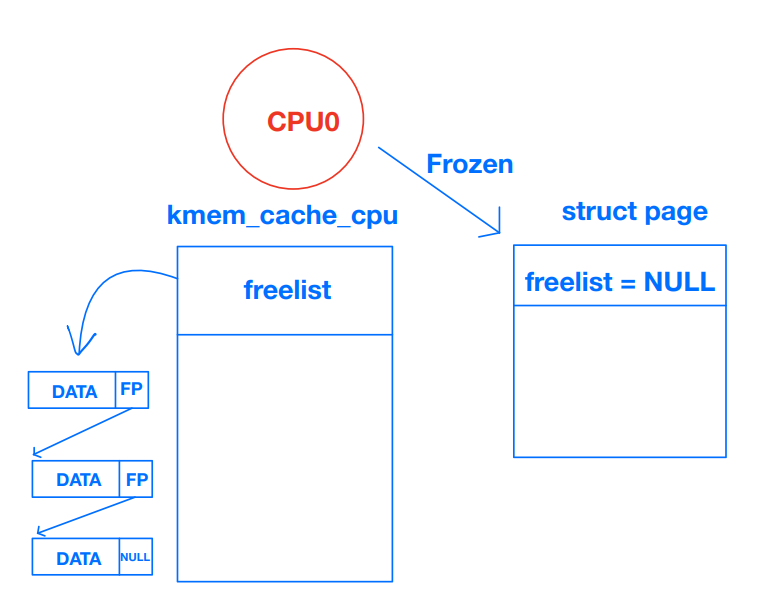
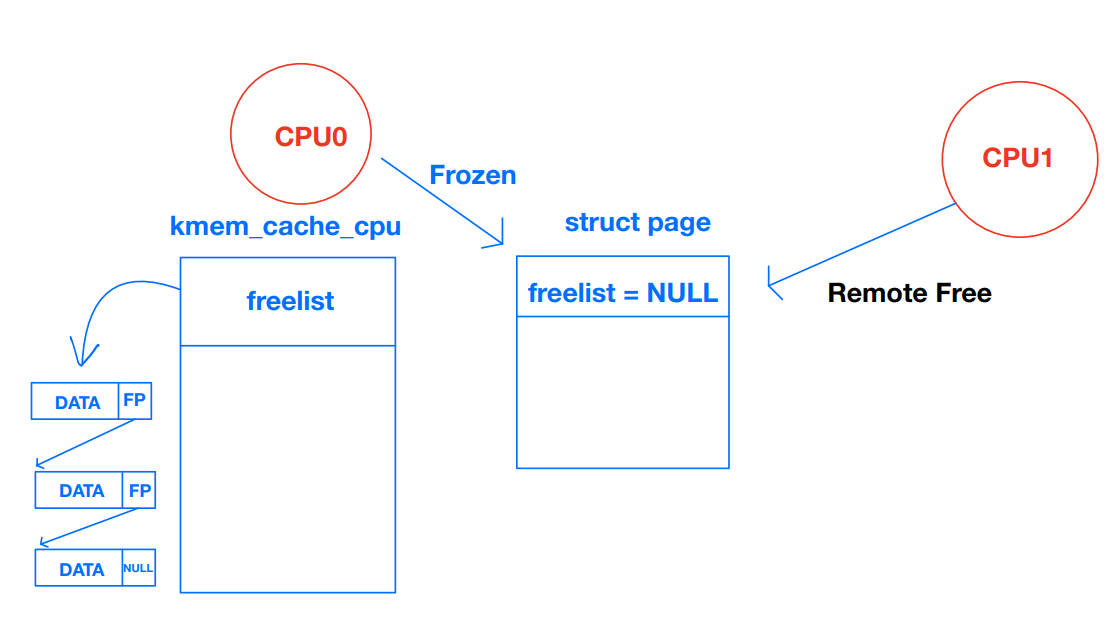
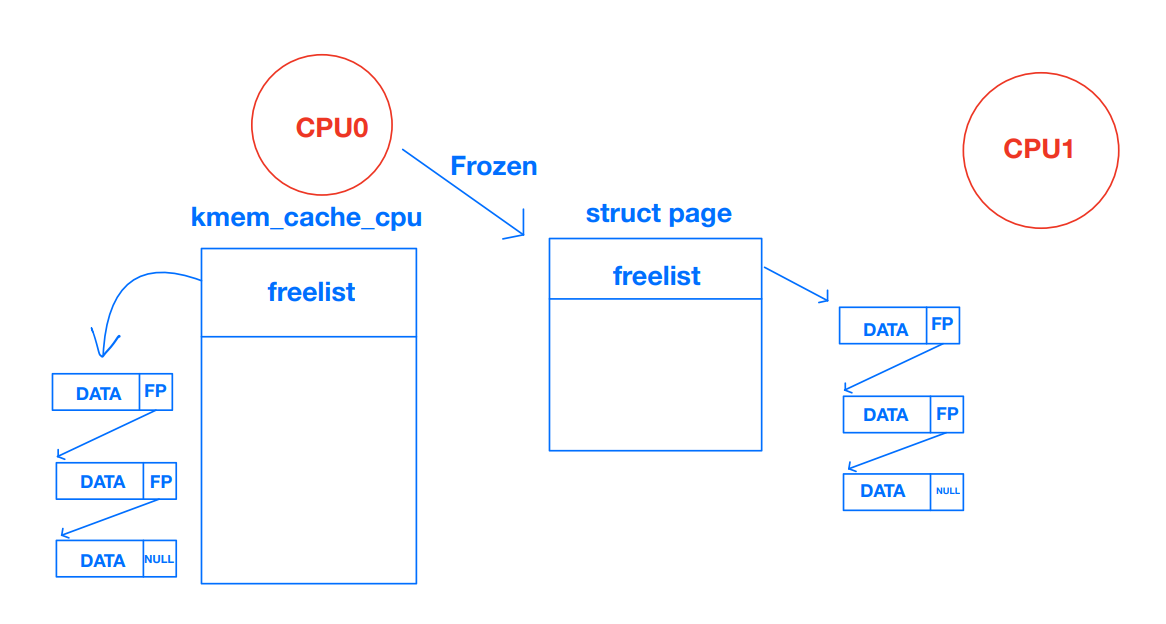
* The list_lock protects the partial and full list on each node and
* the partial slab counter. If taken then no new slabs may be added or
* removed from the lists nor make the number of partial slabs be modified.
* (Note that the total number of slabs is an atomic value that may be
* modified without taking the list lock).
*
* The list_lock is a centralized lock and thus we avoid taking it as
* much as possible. As long as SLUB does not have to handle partial
* slabs, operations can continue without any centralized lock. F.e.
* allocating a long series of objects that fill up slabs does not require
* the list lock.
* Interrupts are disabled during allocation and deallocation in order to
* make the slab allocator safe to use in the context of an irq. In addition
* interrupts are disabled to ensure that the processor does not change
* while handling per_cpu slabs, due to kernel preemption.list_lock은 매우 광범위한 락으로 각각의 NUMA 노드와 partial slab counter에서 partial, full 리스트를 관리하는데 사용된다. list_lock을 획득하면 반납하기 전까지는 리스트에 새로운 원소가 추가되지 않는다. (단, 총 슬랩의 개수는 atomic 변수라 list_lock과 관계없이 변할 수 있다.)
* SLUB assigns one slab for allocation to each processor.
* Allocations only occur from these slabs called cpu slabs.
*
* Slabs with free elements are kept on a partial list and during regular
* operations no list for full slabs is used. If an object in a full slab is
* freed then the slab will show up again on the partial lists.
* We track full slabs for debugging purposes though because otherwise we
* cannot scan all objects.
*
* Slabs are freed when they become empty. Teardown and setup is
* minimal so we rely on the page allocators per cpu caches for
* fast frees and allocs.SLUB은 하나의 슬랩을 프로세서에게 할당한다. free element가 존재하는 슬랩은 partial list에서 찾을 수 있고, 더이상 할당이 불가능한 full slab은 리스트에 존재하지 않다가 오브젝트가 free되면 partial list로 다시 삽입된다. full slab도 추적은 가능하나 partial list를 순회할 때 full slab은 필요가 없으므로 빼놓았다.
* page->frozen The slab is frozen and exempt from list processing.
* This means that the slab is dedicated to a purpose
* such as satisfying allocations for a specific
* processor. Objects may be freed in the slab while
* it is frozen but slab_free will then skip the usual
* list operations. It is up to the processor holding
* the slab to integrate the slab into the slab lists
* when the slab is no longer needed.위에서 잠깐 언급했듯 struct page에는 슬랩과 관련된 필드도 일부 있다. 그중 page->frozen이 1인 경우에는 현재 프로세서가 해당 페이지를 사용하는 슬랩을 freeze한 것이다. (다른 프로세서는 할당은 불가능하고 해제만 가능하다.) 다른 프로세서가 free를 할 때도 슬랩의 리스트를 수정하지는 않는다. 리스트를 관리하는건 그 슬랩을 담당하는 프로세서가 할 일이기 때문이다.
* One use of this flag is to mark slabs that are
* used for allocations. Then such a slab becomes a cpu
* slab. The cpu slab may be equipped with an additional
* freelist that allows lockless access to
* free objects in addition to the regular freelist
* that requires the slab lock.page->frozen가 1이면 현재 해당 슬랩이 할당에 사용중이라는 의미가 된다. 그럼 그 슬랩은 cpu slab이 되고 (struct kmem_cache_cpu의 cpu_slab 필드), cpu slab은 freelist를 갖고 있어서 lockless하게 할당할 수 있다. (일반적으로는 락이 필요한데 fastpath에서는 lockless가 가능)아까 위에서 본 사진을 다시 보자.
* SLAB_DEBUG_FLAGS Slab requires special handling due to debug
* options set. This moves slab handling out of
* the fast path and disables lockless freelists.
*/SLAB_DEBUG_FLAGS를 슬랩을 생성할 때 설정한 경우 디버깅을 위해 fastpath와 lockless freelist를 사용하지 않는다.
What is CPU Partial in SLUB?
코드나 커밋 로그를 보면 cpu partial이라는 말이 종종 나온다. CONFIG_SLUB_CPU_PARTIAL으로 활성화할 수 있다. 그런데 아쉽게도 주석에는 설명이 없다. 우선 config의 도움말을 보자.
Per cpu partial caches accelerate objects allocation and freeing that is
local to a processor at the price of more indeterminism in the latency of the free.
On overflow these caches will be cleared which requires the taking of locks
that may cause latency spikes. Typically one would choose no for a realtime system.Per cpu partial cache는 할당과 해제의 속도를 빠르게 해주는 대신 free의 latency를 비결정적으로 만든다. 따라서 RT에서는 잘 선택하지 않을 것이다. 오버플로우시에는 per cpu partial cache를 모두 비우는데, 이때 락을 사용해서 latency가 급격하게 늘어난다.
하지만 도움말을 봐도 구조는 상상이 잘 안된다. 이해를 위해 cpu partial을 도입한 패치의 설명을 보자.
Allow filling out the rest of the kmem_cache_cpu cacheline with pointers to
partial pages. The partial page list is used in slab_free() to avoid
per node lock taking.partial page list는 partial list를 NUMA 노드별로 관리했는데, slab_free에서 오브젝트를 해제할 때 per-node 락은 너무 lock contention이 심하기 때문에 per cpu locking을 하기 위해서 도입한것 이다.
In __slab_alloc() we can then take multiple partial pages off the per
node partial list in one go reducing node lock pressure.
We can also use the per cpu partial list in slab_alloc() to avoid scanning
partial lists for pages with free objects.
The main effect of a per cpu partial list is that the per node list_lock
is taken for batches of partial pages instead of individual ones.
__slab_alloc에서는 partial list에서 여러 개의 페이지를 가져와서 위에서 언급한 lock contention을 줄인다. 그리고 slab_alloc에서도 free object를 찾느라 순회하지 않아도 된다.
Performance:
Before After
./hackbench 100 process 200000
Time: 1953.047 1564.614
./hackbench 100 process 20000
Time: 207.176 156.940
./hackbench 100 process 20000
Time: 204.468 156.940
./hackbench 100 process 20000
Time: 204.879 158.772
./hackbench 10 process 20000
Time: 20.153 15.853
./hackbench 10 process 20000
Time: 20.153 15.986
./hackbench 10 process 20000
Time: 19.363 16.111
./hackbench 1 process 20000
Time: 2.518 2.307
./hackbench 1 process 20000
Time: 2.258 2.339
./hackbench 1 process 20000
Time: 2.864 2.163당시에 (SMP에서) hackbench상의 성능을 25% 가량 개선한 것으로 보인다.
Some functions
할당과 해제를 분석하기 전에 할당, 해제에서 호출하는 함수 몇개를 먼저 분석해보자.
*cmpxchg_double
왜 그냥 cmpxchg_double이 아니라 *cmpxchg_double이라고 적었냐면 변종 함수가 많기 때문이다. 하지만 하는 일 자체는 똑같다. cmpxchg_double은 락 없이 atomic하게 두 개의 변수를 쓸때 사용한다.
!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))예를 들어서 위의 this_cpu_cmpxchg_double은
s->cpu_slab->freelist를 기존의 object에서 next_object로 갱신하고,
s->cpu_slab->tid를 tid에서 next_tid(tid)로 갱신한다.
이때 freelist와 tid의 갱신은 atomic하게 이루어진다.
다만 cmpxchg_double은 몇가지 이유로 실패할 수 있다. 대부분의 이유는 아키텍처에 의존적이라 나도 잘 모르지만, SLUB을 분석하면서 알아야 하는 것은 (s->cpu_slab->freelist != object) || (s->cpu_slab->tid != tid)인 경우에는 실패한다는 점이다. 해당 경우에는 선점으로 인해 object나 tid가 서로 다른 슬랩으로부터 읽힌 것이므로 실패하게 된다. 즉, 갚을 덮어쓰기 전에 기존에 읽어온 값이 변수의 실제 값과 일치하는지 확인한다.
get_freepointer
void *get_freepointer(struct kmem_cache *s, void *object)get_freepointer는 특정 object의 FP (Free Pointer)를 가져오는 함수이다. FP는 오브젝트의 중간 또는 바깥에 있는데, 해당 정보는 s->offset에 있으므로 (object + s->offset)을 역참조하여 FP를 가져온다.
set_freepointer
void set_freepointer(struct kmem_cache *s, void *object, void *fp)set_freepointer는 오브젝트의 FP 위치에 포인터를 저장한다.
pfmemalloc_match
여기서 pfmemalloc_match가 pfmemalloc은 페이지에 설정하는 플래그로 메모리를 free할 때 사용될 목적으로 reserved된 페이지에 설정하는 플래그이다. 따라서 위의 코드는 현재 CPU가 담당하는 페이지가 pfmemalloc으로 reserved된 경우, 다른 슬랩에서 할당한다.
What is the use of flag PF_MEMALLOC
When I am browsing some code in one device driver in linux, I found the flag PF_MEMALLOC is being set in the thread (process). I found the definition of this flag in header file, which saying that "
stackoverflow.com
deactivate_slab
void deactivate_slab(struct kmem_cache *s, struct page *page,
void *freelist, struct kmem_cache_cpu *c)deactivate_slab은 cpu_slab을 node의 partial list에 삽입하거나 할당된 오브젝트가 없어서 해제할 수 있는 슬랩인 경우 discard_slab으로 해제한다.
discard_slab
void discard_slab(struct kmem_cache *s, struct page *page)discard_slab은 슬랩과 관련된 데이터를 정리하고 페이지를 페이지 할당자에게 반환한다.
Allocation
이제 할당과 해제가 어떻게 이루어지는지 살펴볼 준비가 된것같다.
할당에서의 호출은 kmem_cache_alloc -> slab_alloc -> slab_alloc_node -> __slab_alloc_node -> ___slab_alloc_node 순서로 이루어진다.
kmem_cache_alloc
void *kmem_cache_alloc(struct kmem_cache *s, gfp_t gfpflags)
{
void *ret = slab_alloc(s, gfpflags, _RET_IP_, s->object_size);
trace_kmem_cache_alloc(_RET_IP_, ret, s->object_size,
s->size, gfpflags);
return ret;
}
EXPORT_SYMBOL(kmem_cache_alloc);slab_alloc
static __always_inline void *slab_alloc(struct kmem_cache *s,
gfp_t gfpflags, unsigned long addr, size_t orig_size)
{
return slab_alloc_node(s, gfpflags, NUMA_NO_NODE, addr, orig_size);
}참고로 NUMA_NO_NODE는 노드를 지정하지 않는 매크로로 값은 -1이다.
slab_alloc_node
/*
* Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc)
* have the fastpath folded into their functions. So no function call
* overhead for requests that can be satisfied on the fastpath.
*
* The fastpath works by first checking if the lockless freelist can be used.
* If not then __slab_alloc is called for slow processing.
*
* Otherwise we can simply pick the next object from the lockless free list.
*/slab_alloc_node에서는 lockless freelist를 사용할 수 있는지 먼저 확인하고, 불가능하면 __slab_alloc을 호출해서 slowpath를 처리한다. fastpath에서 함수 호출을 안하기위해 인라인 함수로 정의되어있다.
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
struct obj_cgroup *objcg = NULL;
bool init = false;
s = slab_pre_alloc_hook(s, &objcg, 1, gfpflags);
if (!s)
return NULL;
object = kfence_alloc(s, orig_size, gfpflags);
if (unlikely(object))
goto out;초반부는 memcg, kfence에서의 hook이므로 스킵하겠다.
redo:
/*
* Must read kmem_cache cpu data via this cpu ptr. Preemption is
* enabled. We may switch back and forth between cpus while
* reading from one cpu area. That does not matter as long
* as we end up on the original cpu again when doing the cmpxchg.
*
* We should guarantee that tid and kmem_cache are retrieved on
* the same cpu. It could be different if CONFIG_PREEMPTION so we need
* to check if it is matched or not.
*/
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPTION) &&
unlikely(tid != READ_ONCE(c->tid)));이 부분에서는 cpu_slab과 tid를 읽어온다. while문으로 반복해서 읽어오는 이유는 존재하는 이유는 락을 사용하지 않기 때문에 선점될 수 있기 때문이다. 이때 tid는 유니크한 transaction id로 lockless fastpath를 처리할 때 선점되었는지를 확인하는 데에사용된다.
/*
* Irqless object alloc/free algorithm used here depends on sequence
* of fetching cpu_slab's data. tid should be fetched before anything
* on c to guarantee that object and page associated with previous tid
* won't be used with current tid. If we fetch tid first, object and
* page could be one associated with next tid and our alloc/free
* request will be failed. In this case, we will retry. So, no problem.
*/
barrier();memory barrier는 컴파일러나 프로세서가 임의로 명령어의 순서를 바꾸지 못하게 한다. 여기서 barrier가 사용되는 이유는 c->freelist와 c->page보다 tid가 먼저 fetch되어야 하기 때문이다. ㅡ 라고 주석에 써있긴 한데 아직 정확한 이유는 모르겠다. 내 생각엔 tid가 겹처도 cmpxchg_double이 검증을 해줄텐데 어떤 맥락에서 추가된건지 잘 모르겠다.
/*
* The transaction ids are globally unique per cpu and per operation on
* a per cpu queue. Thus they can be guarantee that the cmpxchg_double
* occurs on the right processor and that there was no operation on the
* linked list in between.
*/
object = c->freelist;
page = c->page;
if (unlikely(!object || !page || !node_match(page, node))) {
object = __slab_alloc(s, gfpflags, node, addr, c);
CPU의 freelist가 비어있거나 (!object), CPU가 슬랩을 freeze하지 않았거나 (!page) slab_alloc_node에 요청한 노드와 현재 CPU가 담당한 페이지의 노드가 다른 경우(!node_match(page, node))에는 __slab_alloc을 호출해서 slowpath를 처리한다.
} else {
void *next_object = get_freepointer_safe(s, object);get_freepointer{,_safe}는 object의 next free object를 가져오는 함수이다. allocation을 한 후에는 freelist가 리스트의 다음 오브젝트를 가리켜야 하므로 next_object를 불러온다.
/*
* The cmpxchg will only match if there was no additional
* operation and if we are on the right processor.
*
* The cmpxchg does the following atomically (without lock
* semantics!)
* 1. Relocate first pointer to the current per cpu area.
* 2. Verify that tid and freelist have not been changed
* 3. If they were not changed replace tid and freelist
*
* Since this is without lock semantics the protection is only
* against code executing on this cpu *not* from access by
* other cpus.
*/
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) {
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}this_cpu_cmpxchg_double은 s->cpu_slab의 freelist와 tid를 교체하기 위해 사용된다. object를 next_object로, tid를 next tid로 교체하는데 atomic하게 교체하므로 락이 필요하지 않다.
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH);
}prefetch_freepointer는 allocation이 빠르게 일어나는 경우에 next object의 free pointer (next_object의 다음 free object)를 캐시라인으로 불러와서 메모리 접근으로 인한 지연 시간을 줄이고자 사용된다. stat은 fastpath를 처리했다는 통계를 기록하기 위한 코드이다.
maybe_wipe_obj_freeptr(s, object);
init = slab_want_init_on_alloc(gfpflags, s);
out:
slab_post_alloc_hook(s, objcg, gfpflags, 1, &object, init);
return object;
}할당이 끝나면 오브젝트의 조건부로 free pointer를 초기화해주고, 조건부로 할당시의 오브젝트를 초기화한다.
__slab_alloc
위에서 살펴봤듯 slab_alloc_node에서 fastpath가 불가능하면 __slab_alloc으로 slowpath를 처리한다. __slab_alloc은 인터럽트가 비활성화되지 않았을 때 호출하는 함수이다. 이미 인터럽트가 비활성화된걸 안다면 ___slab_alloc을 호출할 수 있다.
/*
* Another one that disabled interrupt and compensates for possible
* cpu changes by refetching the per cpu area pointer.
*/
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *p;
unsigned long flags;
local_irq_save(flags);
#ifdef CONFIG_PREEMPTION
/*
* We may have been preempted and rescheduled on a different
* cpu before disabling interrupts. Need to reload cpu area
* pointer.
*/
c = this_cpu_ptr(s->cpu_slab);
#endif
p = ___slab_alloc(s, gfpflags, node, addr, c);
local_irq_restore(flags);
return p;
}___slab_alloc
/*
* Slow path. The lockless freelist is empty or we need to perform
* debugging duties.
*
* Processing is still very fast if new objects have been freed to the
* regular freelist. In that case we simply take over the regular freelist
* as the lockless freelist and zap the regular freelist.
*___slab_alloc은 slowpath를 처리한다. 근데 slowpath도 여러 케이스가 있는데, 아래 사진처럼 페이지의 freelist (regular freelist)에 오브젝트가 있는 경우에는 다른 경우보다 좀더 빨리 처리할 수 있다.

* If that is not working then we fall back to the partial lists. We take the
* first element of the freelist as the object to allocate now and move the
* rest of the freelist to the lockless freelist.그게 불가능하면 이제 partial list에서 슬랩을 freeze한 다음에 freelist의 첫 번째 오브젝트를 할당하고 나머지를 lockless freelist (kmem_cache_cpu의 freelist)로 가져온다.
*
* And if we were unable to get a new slab from the partial slab lists then
* we need to allocate a new slab. This is the slowest path since it involves
* a call to the page allocator and the setup of a new slab.
*
* Version of __slab_alloc to use when we know that interrupts are
* already disabled (which is the case for bulk allocation).
*/그리고 만약 partial slab list에서 슬랩을 못가져오면 새로 슬랩을 만들어야 한다. 이건 페이지 할당자에서 페이지를 할당해와야하기 때문에 slowpath중 가장 느리다.
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
stat(s, ALLOC_SLOWPATH);
page = c->page;
if (!page) {
/*
* if the node is not online or has no normal memory, just
* ignore the node constraint
*/
if (unlikely(node != NUMA_NO_NODE &&
!node_isset(node, slab_nodes)))
node = NUMA_NO_NODE;
goto new_slab;
}현재 CPU가 담당하는 슬랩이 없으면 다른 슬랩을 찾아서 할당한다. 이때 요청한 NUMA 노드에 메모리가 부족하거나 사용할 수 없는 경우에는 임의의 노드에서 할당한다.
redo:
if (unlikely(!node_match(page, node))) {
/*
* same as above but node_match() being false already
* implies node != NUMA_NO_NODE
*/
if (!node_isset(node, slab_nodes)) {
node = NUMA_NO_NODE;
goto redo;
} else {
stat(s, ALLOC_NODE_MISMATCH);
deactivate_slab(s, page, c->freelist, c);
goto new_slab;
}
}___slab_alloc의 인자 node와 현재 CPU가 담당하는 슬랩의 NUMA 노드가 일치하지 않는 경우에는 node로부터 할당을 시도한다. 단, node에서 할당할 수 없는 경우에는 임의의 노드에서 할당한다 (NUMA_NO_NODE)
이때 deactivate_slab은 현재 CPU가 담당하는 슬랩을 unfreeze하는 것이다. 슬랩을 해제하는 것은 아니고 node의 partial list로 돌아간다.
/*
* By rights, we should be searching for a slab page that was
* PFMEMALLOC but right now, we are losing the pfmemalloc
* information when the page leaves the per-cpu allocator
*/
if (unlikely(!pfmemalloc_match(page, gfpflags))) {
deactivate_slab(s, page, c->freelist, c);
goto new_slab;
}현재 페이지가 pfmemalloc을 위한 페이지라면 deactivate하고 다른 슬랩에서 할당한다.
/* must check again c->freelist in case of cpu migration or IRQ */
freelist = c->freelist;
if (freelist)
goto load_freelist;__slab_alloc을 호출하기 직전에 선점이 되었을 수 있으므로 c->freelist를 다시 읽어온다. 그 후 load_freelist에서 오브젝트를 할당한다.
freelist = get_freelist(s, page);
if (!freelist) {
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
stat(s, ALLOC_REFILL);여기까지 오면 적어도 CPU의 lockless freelist에는 오브젝트가 없는 것이므로, 페이지의 freelist를 가져온다. 그런데 페이지의 freelist도 비어있으면 new_slab으로 가서 다른 슬랩에서 할당을 시도한다.
load_freelist:
/*
* freelist is pointing to the list of objects to be used.
* page is pointing to the page from which the objects are obtained.
* That page must be frozen for per cpu allocations to work.
*/
VM_BUG_ON(!c->page->frozen);
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
return freelist;load_freelist에서는 freelist에서 오브젝트를 하나 꺼낸 뒤, 그 다음 오브젝트를 c->freelist로 저장한다. 이때 freelist 변수는 c->freelist에서 가져온 것일 수도 있고, page->freelist에서 가져온 것일 수도 있다.
new_slab:
if (slub_percpu_partial(c)) {
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}우선 위에서 아까 말했듯 per node locking은 너무 비용이 크므로 cpu partial list에서 슬랩을 가져온다. 가져왔을 경우 redo로 가서 처음부터 다시 반복한다.
freelist = new_slab_objects(s, gfpflags, node, &c);
if (unlikely(!freelist)) {
slab_out_of_memory(s, gfpflags, node);
return NULL;
}cpu partial을 사용하지 않거나 cpu partial list에도 슬랩이 없는 경우에는 new_slab_objects 새로운 오브젝트를 할당하는데, new_slab_objects는 per node partial list에서 슬랩을 가져온 후 오브젝트를 할당하거나, 그게 실패하면 페이지를 새로 할당받아서 슬랩을 새로 만들어준다.
page = c->page;
if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags)))
goto load_freelist;이제 CPU가 담당하는 슬랩이 생겼다. pfmemalloc_match가 참인 경우에는 load_freelist에서 오브젝트를 할당한다.
/* Only entered in the debug case */
if (kmem_cache_debug(s) &&
!alloc_debug_processing(s, page, freelist, addr))
goto new_slab; /* Slab failed checks. Next slab needed */
deactivate_slab(s, page, get_freepointer(s, freelist), c);
return freelist;
}이 부분은 pfmemalloc_match가 참일 때만 (또는 디버깅시에) 실행되는데, 새로 할당한 페이지가 pfmemalloc으로 reserved된 경우에는 오브젝트를 하나만 할당하고 다시 슬랩을 deactivate_slab으로 unfreeze하여 다음 할당에서는 해당 슬랩이 사용되지 않도록 한다.
Free
이제 free를 분석해보자. alloc이랑 반대라고 생각하면 크게 어렵진 않을 것이다.
kmem_cache_free
void kmem_cache_free(struct kmem_cache *s, void *x)
{
s = cache_from_obj(s, x);
if (!s)
return;
slab_free(s, virt_to_head_page(x), x, NULL, 1, _RET_IP_);
trace_kmem_cache_free(_RET_IP_, x, s->name);
}
EXPORT_SYMBOL(kmem_cache_free);slab_free
static __always_inline void slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
/*
* With KASAN enabled slab_free_freelist_hook modifies the freelist
* to remove objects, whose reuse must be delayed.
*/
if (slab_free_freelist_hook(s, &head, &tail))
do_slab_free(s, page, head, tail, cnt, addr);
}do_slab_free
/*
* Fastpath with forced inlining to produce a kfree and kmem_cache_free that
* can perform fastpath freeing without additional function calls.
*
* The fastpath is only possible if we are freeing to the current cpu slab
* of this processor. This typically the case if we have just allocated
* the item before.
*
* If fastpath is not possible then fall back to __slab_free where we deal
* with all sorts of special processing.
*
* Bulk free of a freelist with several objects (all pointing to the
* same page) possible by specifying head and tail ptr, plus objects
* count (cnt). Bulk free indicated by tail pointer being set.
*/slab_alloc처럼 fastpath를 함수호출 없이 처리하기 위해 __always_inline을 사용한다. free에서의 fastpath는 현재 CPU가 담당하는 페이지의 오브젝트를 free할 때만 처리할 수 있다. 따라서 fastpath를 처리하려면 오브젝트의 생애주기가 매우 짧아야 한다. fastpath가 불가능하면 __slab_free를 호출해서 slowpath를 처리한다.
do_slab_free은 head, tail 인자를 통해서 한 번에 여러 오브젝트를 free할 수 있다.
static __always_inline void do_slab_free(struct kmem_cache *s,
struct page *page, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
unsigned long tid;
memcg_slab_free_hook(s, &head, 1);
redo:
/*
* Determine the currently cpus per cpu slab.
* The cpu may change afterward. However that does not matter since
* data is retrieved via this pointer. If we are on the same cpu
* during the cmpxchg then the free will succeed.
*/
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPTION) &&
unlikely(tid != READ_ONCE(c->tid)));
/* Same with comment on barrier() in slab_alloc_node() */
barrier();여기까지는 slab_alloc_node랑 완전히 똑같다.
if (likely(page == c->page)) {
void **freelist = READ_ONCE(c->freelist);
set_freepointer(s, tail_obj, freelist);
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
freelist, tid,
head, next_tid(tid)))) {
note_cmpxchg_failure("slab_free", s, tid);
goto redo;
}
stat(s, FREE_FASTPATH);현재 CPU가 담당하는 슬랩의 오브젝트를 free하는 경우 cmpxchg_double로 빠르게 free할 수 있다 (fastpath)
} else
__slab_free(s, page, head, tail_obj, cnt, addr);
}불가능한 경우 slowpath를 처리한다.
__slab_free
/*
* Slow path handling. This may still be called frequently since objects
* have a longer lifetime than the cpu slabs in most processing loads.
*
* So we still attempt to reduce cache line usage. Just take the slab
* lock and free the item. If there is no additional partial page
* handling required then we can return immediately.
*/__slab_free는 slowpath를 처리한다. slowpath라고는 하지만 오브젝트가 cpu slab보다 생애주기가 더 길면 자주 호출될 수 있다. 따라서 slowpath도 캐시 라인을 덜 사용하려고 노력한다.
static void __slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
void *prior;
int was_frozen;
struct page new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
unsigned long flags;
stat(s, FREE_SLOWPATH);
if (kfence_free(head))
return;
if (kmem_cache_debug(s) &&
!free_debug_processing(s, page, head, tail, cnt, addr))
return; do {
if (unlikely(n)) {
spin_unlock_irqrestore(&n->list_lock, flags);
n = NULL;
}
prior = page->freelist;
counters = page->counters;
set_freepointer(s, tail, prior);
new.counters = counters;
was_frozen = new.frozen;
new.inuse -= cnt;이전의 freelist와 counters를 저장한 후에, 페이지가 기존에 frozen 상태인지를 저장한 후 inuse를 갱신한다. (counters와 inuse/frozen/objects는 union이다.)
if ((!new.inuse || !prior) && !was_frozen) {!prior는 모든 객체가 할당 중이거나, 다른 CPU가 담당중일 때 참이다.
!new.inuse는 지금 free를 하면 full slab (할당된 객체가 없는 슬랩)이 될때 참이 된다.
(!new.inuse || !prior) && !was_frozen은 모든 객체가 할당중이거나 지금 free를 하면 full slab이 될때 참이 된다.
if (kmem_cache_has_cpu_partial(s) && !prior) {
/*
* Slab was on no list before and will be
* partially empty
* We can defer the list move and instead
* freeze it.
*/
new.frozen = 1;
만약 모든 객체가 할당중이던 full 슬랩을 가져왔으며 (!prior) 현재 cpu partial을 사용중이라면 리스트로 바로 보내지 않고 freeze한다.
} else { /* Needs to be taken off a list */
n = get_node(s, page_to_nid(page));
/*
* Speculatively acquire the list_lock.
* If the cmpxchg does not succeed then we may
* drop the list_lock without any processing.
*
* Otherwise the list_lock will synchronize with
* other processors updating the list of slabs.
*/
spin_lock_irqsave(&n->list_lock, flags);
}그런 경우가 아니라면 노드의 리스트 락을 획득한다.
}
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));페이지에 free로 인해 바뀌는 부분(freelist, inuse, frozen)을 갱신한다.
if (likely(!n)) {
if (likely(was_frozen)) {
/*
* The list lock was not taken therefore no list
* activity can be necessary.
*/
stat(s, FREE_FROZEN);
} else if (new.frozen) {
/*
* If we just froze the page then put it onto the
* per cpu partial list.
*/
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
return;
}node의 락을 획득하지 않은 경우에는, free한 오브젝트가 포함된 페이지를 누군가가 freeze하고 있었을 경우에는 그냥 페이지 상의 freelist만 갱신하면 되므로 통계 기록 외에는 아무것도 하지 않는다. 그게 아니라 이번에 CPU가 오브젝트를 free하면서 페이지를 freeze했을 때는 해당 페이지를 cpu partial에 추가한다.
이 다음 부분의 코드는 노드의 list_lock을 획득했을 때만 실행된다.
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
goto slab_empty;만약 슬랩이 full slab이 되었는데 노드에 유지하고 있는 partial slab의 수가 캐시 디스크립터 상의 min_partial보다 크다면 슬랩을 해제한다.
/*
* Objects left in the slab. If it was not on the partial list before
* then add it.
*/
if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {
remove_full(s, n, page);
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
spin_unlock_irqrestore(&n->list_lock, flags);
return;full slab의 오브젝트를 free한 경우에는 n->partial에 존재하지 않으므로 리스트에 추가해준다.
slab_empty:
if (prior) {
/*
* Slab on the partial list.
*/
remove_partial(n, page);
stat(s, FREE_REMOVE_PARTIAL);
} else {
/* Slab must be on the full list */
remove_full(s, n, page);
}
spin_unlock_irqrestore(&n->list_lock, flags);
stat(s, FREE_SLAB);
discard_slab(s, page);
}slab_empty는 리스트 상(기존에 슬랩이 어느 리스트에 있었냐에 따라서 n->partial, n->full에서 지운다.)에서 슬랩을 제거한 후 discard_slab으로 슬랩을 해제한다.
마무리하며
이 글에서는 SLUB의 할당/해제에서의 fastpath와 slowpath를 분석했다. 하지만 SLUB을 100% 분석하지는 않았고 조금 틀린 내용이 있을 수도 있다. 단기간에 모두 이해하긴 어려우므로 천천히 이 글을 유지보수해야겠다.
p.s.
아직도 barrier는 왜 있는지 모르겠다. 아시는 분 계시면 댓글좀..
'Kernel > Slab Allocators' 카테고리의 다른 글
| [Linux Kernel] slab_common 분석 (0) | 2021.10.10 |
|---|---|
| [Linux Kernel] SL[AUO]B: Kernel memory allocator design and philosophy (0) | 2021.10.05 |
| The Slab Allocator: An Object-Caching Kernel Memory Allocator (0) | 2021.10.04 |



댓글